1. java.lang 패키지 (Java language)
- 가장 기본이 되는 클래스들 포함 (import문이 필요없이 사용 가능)
Ex) String, System, ... (를 import없이 사용)
1.1 Object 클래스
- 모든 클래스의 최고 조상, 오직 11개의 메서드만을 가진다.
-> Object클래스의 멤버(멤버변수는 없고 메서드만있음)들은 모든 클래스에서 바로 사용가능하다.
- notify(), wait() 등은 쓰레드와 관련된 메서드이다.
- protected => public으로 바꿔야 오버라이딩 할 수 있다. (안 하면 같은 패키지에서만 쓸 수 있다.)
- 리플렉션 API
1) equals(Object obj)
- 객체 자신(this)과 주어진 객체(obj)를 비교한다. 같으면 true, 다르면 false, (null이 아닐 때만 비교가능)
- 두 객체의 같고 다름을 참조변수의 값으로 판단한다.
-> 그렇기 때문에 서로 다른 두 객체는 항상 주소가 다르다. (결과는 항상 false)
- 주소 값이 아닌 value값을 판단하려면?
-> equals메서드를 오버라이딩하여 주소가 아닌 객체에 저장된 내용을 비교하도록 변경하면 된다.
- equals(Object obj)의 오버라이딩
-> 인스턴스 변수(iv)의 값을 비교하도록 equals를 오버라이딩 해야한다.
Ex)
<hide/>
package javaStudy;
class Value{
int value;
Value(int value){
this.value = value;
}
}
public class EqualsEx {
public static void main(String[] args) {
Value v1 = new Value(10);
Value v2 = new Value(10);
if( v1.equals(v2))
System.out.println("v1과 v2는 같습니다.");
else
System.out.println("v1과 v2는 다릅니다.");
v2 = v1;
if( v1.equals(v2))
System.out.println("v1과 v2는 같습니다.");
else
System.out.println("v1과 v2는 다릅니다.");
}
}Note) 실행 결과

- value라는 멤버변수를 갖는 Value클래스를 정의하고 두 개의 Value클래스의 인스턴스를 생성한 다음
- equals메서드를 이용해서 두 인스턴스를 비교하도록 했다.
- 두 멤버변수의 value값이 10으로 동일하더라도 equals로 비교하면 false가 나올 수 밖에 없다.
- 하지만 v2에 v1을 대입한 후에는 v2에 v1이 참조하고 있는 인스턴스의 주소 값이 저장된다.
- 따라서 둘의 주소 값이 저장된다. 그래서 아래 결과는 true.
Ex9-2) equals메서드 오버라이딩
<hide/>
package javaStudy;
class Person{
long id;
public boolean equals(Object obj) {
if( obj instanceof Person)
return id == ((Person)obj).id; // obj가 Object타입이므로 id값을 참조하기 위해 Person타입으로 형변환
else
return false; // 타입이 Person이 아니면 값을 비교할 필요 없다.
}
Person(long id){
this.id = id;
}
}
public class EqualsEx0 {
public static void main(String[] args) {
Person p1 = new Person(8011081111222L);
Person p2 = new Person(8011081111222L);
if( p1 == p2)
System.out.println("p1과 p2는 같은 사람입니다.");
else
System.out.println("p1과 p2는 다른 사람입니다.");
if( p1.equals(p2))
System.out.println("p1과 p2는 같은 사람입니다.");
else
System.out.println("p1과 p2는 다른 사람입니다.");
}
}
Note) 실행 결과

- equals 를 오버라이딩 함으로써 서로 다른 인스턴스일지라도 같은 id를 가지고 있으면 결과 => true
2) hashCode()
Def) 해싱(hassing)기법에 사용되는 해시함수(hash function)을 구현한 메서드이다.
- 해시함수(hash function): 찾고자하는 값을 입력하면 그 값이 저장된 위치를 알려주는 해시코드(hash code)를 반환.
- 객체의 해시코드를 반환하는 메서드
- Object클래스의 hashCode()는 객체의 주소를 int로 변환해서 반환
- '객체의 지문'이라고도 한다.
- equals()를 오버라이딩하면 hashCode()도 오버라이딩해야한다. (중요)
-> equals()의 결과가 true인 두 객체의 해시코드는 같아야 하기 때문이다.
- identityHashCode(Object obj)는 Object클래스의 hashCode()와 동일하다.
- equals 결과가 true면 해시코드 결과도 똑같이 나와야한다.
- identityHashCode(Object x)는 Object클래스의 hashCode메서드처럼 객체의 주소 값으로 해시코드를 생성
-> 따라서 모든 객체에 대해 항상 다른 해시코드값을 반환할 것을 보장한다.
-> 값은 같더라도 서로 다른 객체인지 확인할 수 있음
3) toString() : 객체를 문자열(String)로 반환하기 위한 메서드
ex) tohexString() : 16진법
-> 객체는 iv의 집합이므로 객체를 문자열로 바꾸는 것은 iv(예제의 kind, number)값을 문자열로 반환한다는 것과 같음.
-> Objects클래스는 객체와 관련된 유용한 메서드를 제공하는 유틸 클래스
Ex)
<hide/>
package javaStudy;
public class ToStringTest {
public static void main(String[] args) {
String str = new String("KOREA");
java.util.Date today = new java.util.Date();
System.out.println(str);
System.out.println(str.toString());
System.out.println(today);
System.out.println(today.toString());
}
}Note) 실행 결과

- String클래스와 Date클래스의 toString을 호출했더니 클래스이름과 해시코드 대신 다른 결과가 출력된다.
- String클래스의 toString은 String인스턴스가 갖고 있는 문자열을 반환하도록 오버라이딩 되어 있다.
- Date클래스의 경우 Date인스턴스가 갖고 있는 날짜와 시간을 문자열로 반환하도록 오버라이딩 되어있다.
- 이처럼 toString은 일반적으로 인스턴스나 클래스에 대한 정보 또는 인스턴스 변수의 값을 문자열로 변환하여
- 반환하도록 오버라이딩 되어 있다.
4) clone() - 얕은 복사
- 자신을 복제하여 새로운 인스턴스를 생성한다. (원래의 인스턴스로 되돌리거나 참고하기 좋음.)
- clone은 단순히 인스턴스의 값만 복사하므로
-> 참조타입의 인스턴스 변수가 있는 클래스는 완전한 인스턴스 복제는 아님
Ex) 배열의 경우,
-> 복제된 인스턴스도 같은 배열의 주소를 갖기 때문에 복제된 인스턴스의 작업이 원래 인스턴스에 영향 준다.
-> 따라서 clone메서드를 오버라이딩해서 새로운 배열을 생성하고 배열의 내용을 복사하도록 해야한다.
- clone() 순서
(1) Clonable 인터페이스를 구현한 클래스에서만 clone()을 호출할 수 있다.
-> 인스턴스의 데이터를 보호하기 위해서
-> Clonable 인터페이스가 구현되어 있다는 건 클래스 작성자가 복제 허용한다는 뜻.
(2) clone은 반드시 예외처리를 해줘야한다.
(3) clone을 오버라이딩하면서 접근 제어자를 protected에서 public으로 변경해야한다.
-> 그래야 상속관계가 없는 다른 클래스에서 clone을 호출 가능.
(4) 조상클래스의 clone()을 호출하는 코드가 포함된 try-catch문을 작성한다.
5) 공변 반환타입(covariant return type)
Def) 오버라이딩할 때 조상메서드의 반환타입을 자손 클래스의 타입으로 변경을 허용하는 것
Ex)
<hide/>
package javaStudy;
import java.util.*;
public class CloneEx2 {
public static void main(String[] args) {
int [] arr = {1, 2, 3, 4, 5};
int [] arrClone = arr.clone(); // 배열 arr을 복제해서 같은 내용의 새로운 배열 만든다.
arrClone[0] = 6;
System.out.println(Arrays.toString(arr));
System.out.println(Arrays.toString(arrClone));
}
}Note) 실행 결과

- clone을 이용해서 배열을 복사하는 예제이다.
- 배열도 객체이기 때문에 동시에 Cloneable인터페이스와 Serializable인터페이스가 구현되어 있다.
- 그래서 Object클래스에는 "protected"로 정의되어 있는 clone배열에서는 "public"으로 오버라이딩하였다.
-> 그래서 예제처럼 오버라이딩했기 때문에 직접 호출 가능하다.
- arraycopy(): 같은 길이의 새로운 배열을 생성한 다음에 arraycopy이용해서 내용을 복사한다.
6) 얕은복사와 깊은 복사
- clone은객체에 저장된 값만 복사할 뿐, 객체가 참조하고 있는 객체까지 복제하지는 못한다.
- 따라서, 객체 배열을 clone()으로 복제하는 경우, 원본과 복제본이 같은 객체를 공유하므로 완전한 복제는 아님.
-> 얕은 복사(shallow copy): 원본을 변경하면 복사본도 영향을 받는다.
- 깊은 복사(deep copy): 원본이 참조하고 있는 객체까지 복제하는 것
-> 원본과 복사본이 서로 다른 객체를 참조한다. => 원본 변경이 복사본에 영향 X
Ex)
<hide/>
package javaStudy;
class Circle implements Cloneable{
Point p; // 원점
double r; // 반지름
Circle( Point p, double r){
this.p = p;
this.r = r;
}
public Circle ShallowCopy() { // 얕은 복사
Object obj = null;
try {
obj = super.clone();
}catch(CloneNotSupportedException e) {}
return (Circle) obj;
}
public Circle DeepCopy() { // 깊은 복사
Object obj = null;
try {
obj = super.clone();
}catch(CloneNotSupportedException e) {}
Circle c = (Circle)obj;
c.p = new Point( this.p.x , this.p.y );
return c;
}
public String toString() {
return "[p=" + p + ", r = " + r + "]";
}
}
class Point{
int x, y;
Point(int x, int y){
this.x = x;
this.y = y;
}
public String toString() {
return "(" + x + "," + y + ")";
}
}
public class ShallowDeepCopy {
public static void main(String[] args) {
Circle c1 = new Circle(new Point(1, 1) , 2.0);
Circle c2 = c1.ShallowCopy();
Circle c3 = c1.DeepCopy();
System.out.println("c1 = "+ c1);
System.out.println("c2 = "+ c2);
System.out.println("c3 = "+ c3);
c1.p.x = 9;
c1.p.y = 9;
System.out.println("= c1의 변경 후 =");
System.out.println("c1 = " + c1);
System.out.println("c2 = "+ c2);
System.out.println("c3 = "+ c3);
}
}Note) 실행 결과

- 인스턴스 c1을 생성한 후, 얕은복사로 c2생성, 깉은 복사로 c3을 생성
- 다음으로 c1이 가리키고 잇는 Point 인스턴스의 x와 y의 값을 9로 변경
- 얕은 복사는 단순히 Object클래스의 clone를 복사한다.
- 깊은 복사는 얕은 복사에 두 줄을 추가하여 복제된 객체가 새로운 인스턴스를 참고하도록 했다.
- 원본이 참조하는 객체까지 복사한 것이다.
7) getClass()
- 자신이 속한 클래스의 Class객체를 반환하는 메서드
-> Class객체는 이름이 'Class'인 객체이다.
- Class객체는 클래스의 모든 정보를 담고 있으며 클래스당 1개만 존재한다.
-> 클래스 파일을 읽어서 사용하기 편한 형태로 저장
- 클래스 파일이 클래스 로더에 의해 메모리에 올라갈 때 자동으로 생성된다.
-> 클래스 로더: 실행 시에 필요한 클래스를 동적으로 메모리에 로드하는 역할
8) Class객체를 얻는 방법
<hide/>
Class cObj = new Card().getClass(); // 생성된 객체로부터 얻는 방법
Class cObj = Card.class; //클래스 리터럴(.*)로 부터 얻는 방법
Class cObj = Class.forName("Card"); // 클래스 이름으로부터 얻는 방법Ex)
<hide/>
package javaStudy;
final class Card{
String kind;
int num;
Card(){
this("SPADE", 1);
}
Card(String kind, int num){
this.kind = kind;
this.num = num;
}
public String toString() {
return kind + ":" + num;
}
}
public class ClassEx1 {
public static void main(String[] args) throws Exception {
Card c = new Card( "HEART", 3 ); // new연산자로 객체 생성
Card c2 = Card.class.newInstance(); // Class객체를 통해 객체 생성
Class cObj = c.getClass();
System.out.println(c);
System.out.println(c2);
System.out.println(cObj.getName());
System.out.println(cObj.toGenericString());
System.out.println(cObj.toString());
}
}Note) 실행결과

- Class객체를 이용해서 동적으로 객체를 생성하는 예제이다.
- forName() : 특정 클래스 파일을 메모리에 올릴 때 주로 사용한다.
1.2 String클래스
1) 문자열 다루기 위한 클래스
- String클래스는 앞에 final이 붙어 있으므로 다른 클래스의 조상이 될 수 없다.
- String 클래스 = 데이터(char[]) + 메서드(문자열 관련)
- 내용을 변경할 수 없는 불변(immutable) 클래스! (문자열은 내용 변경 불가)
- 한 번 생성된 String인스턴스가 갖고 있는 문자열은 읽어올 수만 있고 변경을 불가능
- 덧셈 연산자(+)를 이용한 문자열 결합은 성능이 떨어짐 (매 연산 시마다 새로운 문자열을 가진 String 인스턴스 생성하기 때문)
- 문자열의 결합이나 변경이 잦다면 내용을 변경 가능한 "StringBuffer"를 사용한다.
2) 문자열의 비교
-> 문자열을 만드는 방벙: 문자열 리터럴을 지정/ String클래스의 생성자를 사용해서 만들기
-> 문자열 리터럴은 이미 존재하는 것을 재사용한다.
-> 대입연산자(주소 비교)가 아닌 equals(내용)로 비교한다.
-> new연산자를 이용해서 문자열을 만들면 내용이 같아도 항상 새로운 문자열이 나온다.
3) 문자열 리터럴 (리터럴은 상수)
-> 모든 문자열 리터럴은 컴파일 시에 클래스 파일에 저장된다.
-> 이 때, 같은 내용의 문자열 리터럴은 한번만 저장된다.
-> 문자열 리터럴은 프로그램 실행 시 자동으로 생성된다. (costant pool - 상수 저장소에 저장된다. )
4) 빈 문자열(empty string)
-> 내용이 없는 문자열, 크기가 0인 char형 배열을 저장하는 문자열
-> 크기가 0인 배열을 생성하는 것은 어느 타입이나 가능하다.
(크기 = 길이라고 본다.)
-> 숫자를 문자로 바꿀 때, 배열 초기화할 때 유용하다.
-> 크기가 0인 String은 가능하나 char형 변수는 반드시 하나 이상의 문자를 지정해야만 한다.
Ex)
<hide/>
package javaStudy;
public class StringEx3 {
public static void main(String[] args) {
//길이가 0인 배열을 생성
char[] cArr = new char[0]; // char[] cArr = {};와 같다.
String s = new String(cArr); // String s = new String("");
System.out.println("cArr.length = " + cArr.length);
System.out.println("@@@" + s + "@@@");
}
}Note) 실행결과

- 길이가 0인 배열을 생성해서 char형 참조변수 cArr을 초기화해줬다.
5) String클래스의 생성자와 메서드
- String(char[] value) : 주어진 문자열(value)을 갖는 String인스턴스를 생성한다.
- String(StringBuffer buf) : StringBuffer 인스턴스가 갖고있는 문자열과 같은 내용의 String인스턴스를 생성한다.
- char charAt(int index) : 지정된 위치(index)에 있는 문자를 알려준다.
- int compareTo(Strings str) : 문자열(str)과 사전 순서로 비교한다.같으면 0 / 사전순으로 이전이면 -1 / 이후면 양수 반환
- boolean contains(charSequence s) : 지정된 문자열(s)이 포함되었는지 검사한다.
- boolean equals(Object obj) : 매개변수로 받은 문자열(obj)과 String인스턴스의 문자열을 비교한다.
-> obj가 String이 아니거나 문자열이 다르면 false를 반환한다.
- boolean equalsIgnoreCase(String str) : 문자열과 String인스턴스의 문자열을 대소문자 구분없이 비교한다.
- int (last)indexOf(int ch) : 주어진 문자(ch)가 존재하는지 지정된 위치(pos)부터 확인하여 인덱스를 알려준다.
-> 못 찾으면 -1반환.
-> last는 뒤에서부터 찾아서 인덱스를 알려준다.
- int indexOf(int ch, int pos) : 주어진 문자가 문자열에 존재하는지 확인하여 위치를 알려준다. 없으면 -1을 반환
- int (last)indexOf(String str) : 주어진 문자열이 존재하는지 확인하여 그 인덱스를 알려준다. 없으면 -1반환,
-> 오른쪽부터: last
- String intern() : 문자열을 상수 풀(constant pool)에 등록한다. 이미 상수풀에 같은 값이 있으면 주소값을 반환한다.
- String replaceAll(String regex, String replacement) : 문자열 중에서 지정된 문자열(regex와) 일치하는 것 중, 첫 번째 것만 새로운 문자열(replacement)로 변경한다.
- String[] split(String regex) : 문자열을 지정된 분리자(regex)로 나누어 배열에 담아 반환한다. (join()과 반대로 동작)
Ex)
<hide/>
String str1 = "apple/banana/grape";
String [] str2 = str1.split("/");
- String[] split(String regex, int limit) : 문자열을 지정된 분리자로 나누어 문자 배열에 담아 반환, 문자열 전체를 지정된 수 limit로 자른다.
- boolean startWith(String prefix) :주어진 문자열 prefix로 시작하는지 검사한다.
- String toUpper/LowerCase() : 모든 문자를 대문자/ 소문자로 변환하여 반환.
- String trim() : 문자열의 왼쪽 끝과 오른쪽 끝에 있는 공백을 없앤 결과를 반환한다 (중간 공백은 예외)
- Integer.parseInt("100")과 Integer.valueOf("100"); 결과는 같다.
6) join()과 StringJoiner
- join()은 여러 문자열 사이에 구분자를 넣어서 결합한다.
- 문자열을 자르는 split()와 반대이다.
Ex)
<hide/>
package javaStudy;
import java.util.StringJoiner;
public class StringEx4 {
public static void main(String[] args) {
String animals = "dog, cat, bear";
String[] arr = animals.split(","); // 문자열을 ','로 구분자로 나눠서 배열에 저장
System.out.println(String.join("-", arr)); // 문자열을 '-'로 구분해서 결합
StringJoiner sj = new StringJoiner("/", "[", "]");
for( String s : arr )
sj.add(s);
System.out.println(sj.toString());
}
}Note) 실행 결과

- StringJoiner 클래스를 사용해서 문자열을 결합할 수 있다.
7) 유니코드의 보충문자
- 유니코드는 하나의 문자를 char 타입으로 다루지 못하고 int 타입으로 다룰 수 밖에 없다.
8) 문자 인코딩 변환
- getBytes(String charSetName)를 사용하면 문자열의 문자 인코딩을 다른 인코딩으로 변경 가능
- 자바는 UTF-16을 사용하지만, 문자열 리터럴에 포함되는 문자들은 OS의 인코딩을 사용한다.
- UTF-8은 한글 한 글자를 3Byte로 표현하고 CP949는 2Byte로 표현한다.
9) String.format()
- format()은 형식화된 문자열을 만들어내는 방법이다. (printf()와 사용법이 완전 같다. )
ex)
<hide/>
String display = String.format("이름: %d, 나이: %d, 몸무게: %d");
System.out.print(display);
Ex) 기본형 -> String으로 변환: String.valueOf();
Ex) String -> 기본형으로 변환: Integer.valueOf();
Def) 래퍼 클래스(wrapper class): 기본형 타입의 이름 첫 글자가 대문자인 것, ex) Boolean, Byte, ..
-> 기본형을 감싸는 클래스라는 뜻이다.
Ex)
<hide/>
package javaStudy;
public class StringEx6 {
public static void main(String[] args) {
int iVal = 100;
String strVal = String.valueOf(iVal); // int를 String으로 변환한다.
double dVal = 200.0;
String strVal2 = dVal + ""; // String으로 변환하는 다른 방법
double sum = Integer.parseInt("+" + strVal) + Double.parseDouble(strVal2);
double sum2 = Integer.valueOf(strVal) + Double.valueOf(strVal2);
System.out.println(String.join("" , strVal, "+", strVal2 , "=")+ sum);
System.out.println(strVal + "+" + strVal2 + "=" + sum2);
}
}Note) 실행 결과

- 문자열과 기본형간 변환하는 예시이다.
- parseInt() 나 parseFloat()같은 매서드는 문자열에 공백 또는 문자가 포함된 경우 변환 시 예외 발생 위험 있다.
1.3 StringBuffer클래스와 StringBuilder클래스
(1) StringBuffer: 가변(내용 변경 가능)
-> 멀티스레드 환경에서 문자열을 사용할 때, 많이 쓰인다. (StringBuilder와의 차이)
-> String: 불변(내용 변경 불가)
-> 문자열을 할당했다가 추가로 더하는 연산을 하면 기존 메모리에 추가되는 게 아니라
새로운 메모리에 더해진 문자열의 영역을 잡고 그 주소를 가리킨다.
(이전에 저장되어 있던 부분은 GC - garbage collenctor가 관리한다.)
-> 배열은 길이 변경이 불가능. 공간이 부족하면 새로운 배열을 생성해야한다.
-> StringBuffer는 저장할 문자열의 길이를 고려해서 적절한 크기로 생성해야 한다.
- StringBuffer의 생성자
-> StringBuffer 인스턴스를 생성할 때, 문자열 길이를 고려해서 여유있는 크기로 지정하는 것이 좋다.
-> 버퍼 크기를 지정하지 않으면 16개의 문자를 저장할 수 있는 크기의 버퍼를 생성한다.
- StringBuffer의 변경
(아래 메서드의 반환 타입: StringBuffer)
-> append(): 자신의 주소를 반환한다.
-> delete(); 삭제
-> input(): 삽입
- StringBuffer의 비교
-> StringBuffer는equals()가 오버라이딩 되어있지 않다. (주소비교) - this.obj
-> String으로 변환한 다음, equals()로 비교해야한다.
-> 반면, toString은 오버라이딩 되어 있어서 StringBuffer인스턴스에 호출하면 문자열을 String으로 반환.
- StringBuffer클래스의 생성자와 메서드
-> String과 유사하나 추가 변경, 삭제와 같이 저장된 내용을 변경하도록 하는 메서드가 많다.
-> StringBuffer(int length) : 지정된 개수의 문자를 담을 수 있는 버퍼를 가진 StringBuffer인스턴스를 생성한다.
-> StringBuffer(String str) : 지정된 문자열 값(str)을 갖는 StringBuffer인스턴스를 생성한다.
-> int capacity() : StringBuffer 인스턴스의 버퍼 크기를 알려준다.
-> StringBuffer replace(int start, int end, String str) : 지정된 범위의 문자들을 주어진 문자열로 바꾼다.
-> void setLength(int newLength) :
지정된 길이로 문자열 길이를 변경한다. 길이를 늘리는 경우 나머지 공간을 널문자로 채운다. (\u0000)
-> String toString() : StringBuffer 인스턴스의 문자열을 String으로 반환한다.
-> appendLine(): 줄 바꿈 (append.(System.lineSeperator()) 와 동일하다.)
-> appendFormat(): append(String.format( "", ...))와 동일하다.
(2) StringBuilder클래스
- StringBuffer와 거의 같다. StringBuilder는 쓰레드의 동기화만 뺐다고 보면 된다.
- StringBuffer는 동기화 되어 있다. (동기화: 멀티쓰레드에 안전(thread-safe) 하다. 데이터보호 )
- 멀티쓰레드 프로그램이 아닌 경우, 동기화는 불필요한 성능 저하
->이 때 StringBuffer를 StringBuilder로 바꾸면 성능 향상된다.
-> 성능 향상이 필요한 경우 아니면 굳이 바꾸지 않아도 된다.
1.4 Math 클래스
- Math 클래스의 생성자는 접근 제어자가 private이기 때문에 다른 클래스에서 Math인스턴스를 생성할 수 없다.
- 클래스 내에 인스턴스 변수가 하나도 없어서 인스턴스를 생성할 필요가 없기 때문이다.
- 메서드는 모두 static, 자연 로그와 원주율 두 가지 상수만 정의해 놓았다.
- round()는 항상 소수 첫째자리에서 반올림하여 정수값(long)을 결과로 돌려준다.
- 따라서, 원하는 자리수에서 반올림된 값을 얻기 위해
1) 원래 값에 100을 곱한다.
2) 위의 결과에 Math.round()를 사용한다.
3) 위의 결과를 다시 100.0으로 나눈다.
-> 위의 방법을 이용한다.
- rint (): 소수 첫째 자리에서 반올림하여 가장 가까운 두 정수 중 짝수를 반환한다.
-> 1.5는 올림, 2.5는 버림, 3.5는 올림, 4.5는 버림 => 짝수의 결과가 나온다
-> 반환값이 double이다.
-> 여러 소수를 rint 로 합계 구했을 때, round 이용한것을 비교하면 rint가 정확한 값에 더 가깝다.
- 예외를 발생시키는 메서드
-> 메서드 이름에서 'Exact'가 포함된 메서드: 정수형 간의 연산에서 발생하는 overflow를 감지하기 위해 존재
-> 오버플로우가 발생하면 예외를 발생시킨다.
Ex)
<hide/>
package javaStudy;
import static java.lang.Math.*;
import static java.lang.System.*;
public class MathEx2 {
public static void main(String[] args) {
int i = Integer.MIN_VALUE;
out.println(" i = " + i);
out.println("-i = " + (-i));
try {
out.printf("negateExact(%d) = %d%n" , 10, negateExact(10));
out.printf("negateExact(%d) = %d%n" , -10, negateExact(-10));
out.printf("negateExact(%d) = %d%n" ,i, negateExact(i)); // 예외 발생
}catch(ArithmeticException e) {
out.printf("negateExact(%d) = %d%n", (long)i, negateExact ((long)i ));
// i를 long타입으로 형변환 다음에 negateExact(long a)를 호출
}
}
}Ntoe) 실행 결과

- 변수 i: int타입의 최솟값
- -i를 하면 부호가 바뀌지 않고 i값이 그래로이다.
- 정수형 최솟값에 비트 전환연산자 '~'를 적용하면 최댓값이 되는데 여기에 1을 더했기 때문에 오버플로우가 발생한다.
- 결과를 보면 오버플로우로 인한 예외가 발생했지만, catch블럭에 의해 예외가 올바르게 처리되었다.
Ex) 삼각함수와 지수, 로그
<hide/>
package javaStudy;
import static java.lang.Math.*;
import static java.lang.System.*;
public class MathEx3 {
public static void main(String[] args) {
int x1 = 1, y1 = 1;
int x2 = 2, y2 = 2;
double c = sqrt( pow(x2 - x1 , 2) + pow(y2 - y1, 2) );
double a = c * sin(PI / 4);
double b = c * cos(PI / 4);
// double b = c * cos(toRadians(45));
out.printf("a = %f%n" , a);
out.printf("b = %f%n" , b);
out.printf("c = %f%n" , c);
out.printf("angle = %f rad%n", atan2(a, b) );
out.printf("angle = %f degree%n", atan2(a, b) * 180 / PI);
// out.printf("angle = %f degree%n", toDegrees(atan2(a, b)));
out.printf("24 * log10(2) = %f%n" , 24 * log10(2));
out.printf("53 * log10(2) = %f%n%n" , 53 * log10(2));
}
}Note) 실행결과

- 제곱근을 구해주는 sqrt()와 n제곱을 계산해주는 pow()를 사용해서 식을 구성
- toRadians(): 각도를 라디안으로 변환한다. ( 180º = π rad )
- 삼각함수는 매개변수의 단위기 라디안(radian)이므로 45º를 라디안 단위의 값으로 변환해야 한다.
- float타입의 가수는 23자리(정규화를 통해 1자리 더 확보하면 실제로 24자리)
- double타입은 52 + 1 = 53자리 확보할 수 있다.
1.5 래퍼(wrapper)클래스
- 8개의 기본형을 객체로 다뤄야할 때 사용하는 클래스
- 기본형 값을 감싸는 클래스
- 기본형의 첫 글자를 대문자로 한 것이 클래스의 이름이다.
- 래퍼클래스들은 MAX_VALUE, MIN_VALUE, SIZE, BYTES, TYPE 등의 static 상수를 공통적으로 가진다.
- Number클래스
-> 모든 숫자 래퍼 클래스의 조상이다.
-> 자손 중 BigInteger은 long으로도 다룰 수 없는 큰 범위 정수 다룰 수 있다.
-> BigDecimal은 double로도 다룰 수없는 큰 범위 부동 소수점수를 처리하기 위해 있다.
Ex) 문자열을 숫자로 변환하기
<hide/>
package javaStudy;
public class WrapperEx2 {
public static void main(String[] args) {
int i = new Integer("100").intValue();
int i2 = Integer.parseInt("100");
Integer i3 = Integer.valueOf("100");
int i4 = Integer.parseInt("100", 2);
int i5 = Integer.parseInt("100", 8);
int i6 = Integer.parseInt("100", 16);
int i7 = Integer.parseInt("FF", 16);
// int i8 = Integer.parseInt("FF"); // NumberFormatException 발생
Integer i9 = Integer.valueOf("100", 2);
Integer i10 = Integer.valueOf("100", 8);
Integer i11 = Integer.valueOf("100", 16);
Integer i12 = Integer.valueOf("FF", 16);
// Integer i13 = Integer.valueOf("FF"); // NumberFormatException 발생
System.out.println(i);
System.out.println(i2);
System.out.println(i3);
System.out.println("100(2) -> "+ i4);
System.out.println("100(8) -> " + i5);
System.out.println("100(16) -> " + i6);
System.out.println("FF(16) -> " + i7);
System.out.println("100(2) -> "+ i9);
System.out.println("100(8) -> " + i10);
System.out.println("100(16) -> " + i11);
System.out.println("FF(16) -> " + i12);
}
}Note) 실행 결과

- 16진법에서는 'A ~F'의 문자도 허용한다. -> Integer.parseInt("FF", 16)과 같은 코드가 가능하지만
- 진법을 생략하면 10진수로 간주하기 때문에 Integer.parseInt("FF", 16)에서는 예외가 발생한다.
- 오토박싱 & 언박싱(autoboxing & unboxing)
->오토박싱: 기본형(ex. int) -> 래퍼클러스 Integer 객체로 자동변환
-> 언박싱: 래퍼클러스 Integer -> 기본형 int 로 변환
-> JDK1.5이후에는 기본형과 참조형 연산이 가능해졌다.
Ex)
<hide/>
package javaStudy;
public class WrapperEx3 {
public static void main(String[] args) {
int i = 10;
// 기본형을 참조형으로 형변환(형변환 생략 가능)
Integer intg = (Integer)i; // Inteher intg = Integer.valueOf(i);
Object obj = (Object)i; // Object obj = (Object)Integer.valueOf(i);
Long lng = 100L; // Long lng = new Long(100L);
int i2 = intg + 10; // 참조형과 기본형과의 연산이 가능하다.
long l = intg + lng; // 참조현 간의 덧셈도 가능
Integer intg2 = new Integer(20);
int i3 = (int)intg2;
Integer intg3 = intg2 + i3;
System.out.println("i = " + i);
System.out.println("intg = " + intg);
System.out.println("obj = " + obj);
System.out.println("lng = " + lng);
System.out.println("intg + 10 = " + i2);
System.out.println("intg + lng = " + l);
System.out.println("intg2 = " + intg2);
System.out.println("i3 = " + i3);
System.out.println("intg2 + i3 = " + intg3);
}
}Note) 실행 결과

- 오토 박싱을 이용해서 기본형과 참조형 간의 형변화과 연산을 수행하는 것을 보여준다.
- 기본형과 참조형 뿐만 아니라 참조형과 참조형 간의 연산도 가능핟.
2. 유용한 클래스
2.1 java.util.Objects 클래스
- Object의 보조클래스로 모든 메서드가 'static'이다. 객체의 비교나 널 체크(null check)에 유용하다.
- notNull은 isNull의 반대 ... !Object.isNull(obj)
- requireNonNull()은 해당 객체가 널이 아니어야 하는 경우에 사용한다.
- 만일 객체가 널이면 NullPointException을 발생시킨다.
- compare(): 두 비교 대상이 같으면 0, 크면 양수, 적으면 음수 반환
- deepEquals(): 객체를 재귀적으로 비교해서 다차원 배열의 비교도 가능하다.
Ex)
<hide/>
package javaStudy;
import java.util.*;
import static java.util.Objects.*; // ObjectS클래스의 메서드를 static import
public class ObjectsClass {
public static void main(String[] args) {
String [][] str2D = new String[][] { {"aaa", "bbb"}, {"AAA", "BBB"}};
String [][] str2D_2 = new String[][] { {"aaa", "bbb"}, {"AAA", "BBB"}};
System.out.print("str2D = {");
for(String[] tmp : str2D)
System.out.print(Arrays.toString(tmp));
System.out.println("}");
System.out.print("str2D_2= {");
for(String[] tmp : str2D_2)
System.out.print(Arrays.toString(tmp));
System.out.println("}");
System.out.println("equals(str2D, str2D_2)=" + Objects.equals(str2D, str2D_2));
System.out.println("deepEquals(str2D, str2D_2)=" + Objects.deepEquals(str2D, str2D_2));
System.out.println("isNull(null) =" + isNull(null));
System.out.println("nonNull(null) =" + nonNull(null));
System.out.println("hashCode(null) = "+ Objects.hashCode(null));
System.out.println("toString(null) = "+ Objects.toString(null));
System.out.println("toString(null, \"\")=" + Objects.toString(null, "") );
Comparator c = String.CASE_INSENSITIVE_ORDER; // 대소문자 구분 안하는 비교
System.out.println("compare(\"aa\", \"bb\")=" + compare("aa", "bb", c));
System.out.println("compare(\"bb\", \"aa\")=" + compare("bb", "aa", c));
System.out.println("compare(\"ab\", \"AB\")=" + compare("ab", "AB", c));
}
}Note) 실행 결과

- static import문을 사용했음에도 불구하고 Object클래스의 메서드와 이름이 같은 것들은 충돌이 난다.
- 컴파일러가 구분을 못하기 때문이다. => 클래스의 이름을 붙여줄 수 밖에 없다.
- String 클래스에 상수로 정의되어 있는 Comparator를 이용해 compare()를 호출했다.
- deepEquals()는 객체를 재귀적으로 비교하므로 다차원 배열의 비교도 가능하다.
- toString()도 equals()처럼 내부적으로 널 검사 하는 것을 빼고는 특별한 것이 없다.
- hashCode(): 내부적으로 널 검사하고 Object클래스의 hashCode()를 호출. (널인 경우 0을 반환)
2.2 java.util.Random 클래스
- Math.random()과 Random의 차이는 종자값(seed)을 설정할 수 있다는 것이다.
-> 종자값이 같은 Random인스턴스들은 항상 같은 난수를 같은 순서대로 반환한다.
- Random클래스의 생성자와 메서드
-> 생성자 Random()은 종자값을 System.currentTimeMills()로 하기 때문에 얻는 난수가 달라진다.
-> Random(long seed) : 매개변수 seed를 종자값으로 하는 Random인스턴스를 생성한다.
-> boolean nextBoolean() : boolean타입의 난수를 반환한다.
-> void nextBytes(byte[] bytes) : bytes배열에 byte타입의 난수를 채워서 반환한다.
-> double next Double() : double타입의 난수를 반환한다.
-> double nextGaussian() : 평균은 0.0이고 표준편차는 1.0인 가우시안분포에 따른 double형의 난수 반환,
-> int NextInt() : int타입의 난수를 반환(int의 범위)
-> void setSeed(long seed) : 종자값을 주어진 값(seed)으로 변경한다.
Ex)
<hide/>
package javaStudy;
import java.util.*;
public class RandomEx1 {
public static void main(String[] args) {
Random rand = new Random(1);
Random rand2 = new Random(1);
System.out.println("= rand =");
for(int i = 0; i < 5; ++i)
System.out.println(i + ":" + rand.nextInt());
System.out.println();
System.out.println("= rand2 = ");
for(int i = 0; i < 5; ++i)
System.out.println(i + ":" + rand2.nextInt());
}
}Note) 실행 결과

- Random인스턴스 rand와 rand2가 같은 종자값(seed)을 사용하기 때문에 같은 값들을 같은 순서로 얻는다.
- 같은 종자값을 갖는 Random 인스턴스는 시스템이나 실행시간 등에 관계 없이 항상 같은 순서로 반환할 것을 보장.
Ex)
<hide/>
package javaStudy;
import java.util.*;
public class RandomEx2 {
public static void main(String[] args) {
Random rand = new Random();
int [] number = new int[100];
int [] counter = new int[10];
for(int i = 0;i < number.length; ++i) {
// System.out.print(number[i] = (int)( Math.random() * 10) );
// 0 <= x < 10 범위의 정수 x를 반환
System.out.print(number[i] = rand.nextInt(10));
}
System.out.println();
for(int i =0 ; i < number.length; ++i)
++counter[number[i]];
for(int i = 0; i < counter.length; ++i)
System.out.println(i + "의 개수: " + printGraph('#', counter[i]) + " " + counter[i] );
}
public static String printGraph(char ch, int value) {
char[] bar = new char[value];
for(int i =0 ; i < bar.length; ++i)
bar[i] = ch;
return new String(bar);
}
}Note) 실행 결과

- 0~9 사이의 난수를 100개 발생시키고 각 숫자를 카운트해서 그래프를 그린다.
- nextInt(int n)는 0부터 n사이의 정수를 반환한다. (n은 포함하지 않는다. )
2.3 정규식(Regular Expression) - java.util.regex 패키지
- 정규식: 텍스트 데이터 중에서 원하는 조건과 일치하는 문자열을 찾아내기 위해 사용하는 것으로 미리 정의된 기호와 문자를 이용해서 작성한 문자열을 말한다.
Ex)
<hide/>
package javaStudy;
import java.util.regex.*;
public class RegularEx2 {
public static void main(String[] args) {
String[] data = {"bat", "baby","bonus", "c", "cA", "ca", "co", "c.", "c0", "c#", "car", "combat", "count", "date", "disc" };
String[] pattern = {".*", "c[a-z]*", "c[a-z]", "c[a-zA-Z]", "c[a-zA-Z0-9]", "c.", "c.*" , "c\\.", "c\\w", "c\\d",
"c.*t", "[b|c].*", ".*a.*" , ".*a.+", "[b|c].{2}" };
for(int x= 0;x < pattern.length; ++x) {
Pattern p = Pattern.compile(pattern[x]);
System.out.print("Pattern : " +pattern[x] + " 결과: ");
for(int i = 0;i < data.length; ++i) {
Matcher m = p.matcher(data[i]);
if(m.matches())
System.out.print(data[i] + ",");
}
System.out.println();
}
}
}Note) 실행 결과
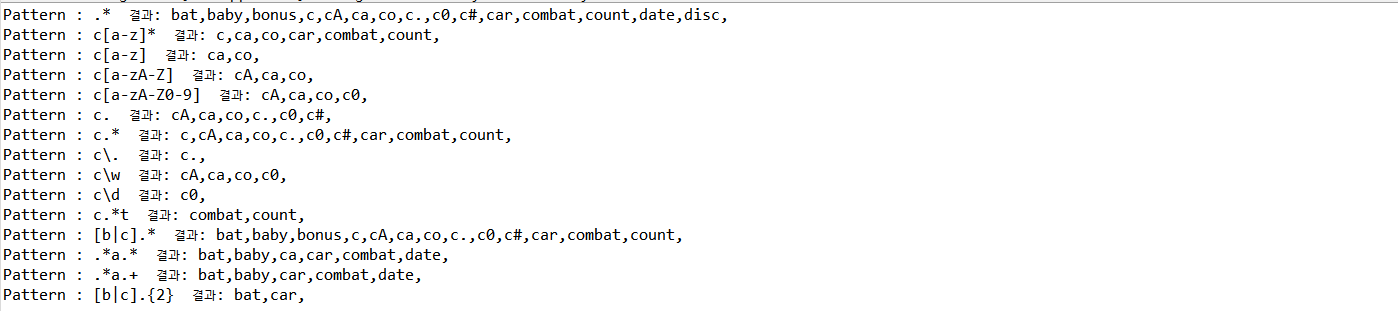
- Pattern, Matcher가 속한 패키지 regex를 import한다.
- ""(큰따옴표)내에서 escape문자 '\'를 표현하려면 '\\'와 같이 두 번 쓴다.
- find()는 주어진 소스 내에서 패턴과 일치하는 부분을 찾으면 true를 반환하고 찾지 못하면 false를 반환한다.
2.4 java.util.Scanner 클래스
- Scanners는 화면, 파일, 문자열과 같은 입력소스로부터 문자데이터를 읽어오는 데 도움 줄 목적으로 사용,
- 숫자 입력: nextLine() / nextInt() / nextLong()
2.5 java.util.StringTokenizer클래스
- StringTokenizer는 긴 문자열을 지정된 구분자(delimiter)를 기준으로 토큰(token)이라는 여러 개의 문자열로 자르는데 이용한다.
- StringTokenizer는 구분자로 "단 하나의 문자"밖에 사용하지 못한다는점이 있다.
-> 구분자가 두 문자 이상이라면 Scanner나 String클래스의 split 메서드를 사용한다.
- 복잡한 형태의 구분자로 문자열을 나눠야할 때는 정규식을 사용하는 메서드를 사용해야 한다.
- StringTokenizer의 생성자와 메서드
-> StringTokenizer(String str, String delim): 문자열을 지정된 구분자로 나누는 StringTokenizer를 생성
-> StringTokenizer(String str, String delim, boolean returnDelims) : returnDelims을 true로 하면 구분자도 토큰 간주
-> int countTokens() : 전체 토큰의 수를 반환한다.
-> String nextToken() : 다음 토큰을 반환한다.
Ex)
<hide/>
package javaStudy;
import java.util.StringTokenizer;
public class StringTokenizerEx1 {
public static void main(String[] args) {
String source = "100,200,300,400";
StringTokenizer st = new StringTokenizer(source, "," );
while(st.hasMoreTokens()) {
System.out.println(st.nextToken());
}
}
}Note) 실행 결과

- ','로 구분자로 하는 StringTokenizer를 생성해서 문자열은 나눠 출력한다.
Ex)
<hide/>
package javaStudy;
import java.util.*;
public class StringTokenizerEx4 {
public static void main(String[] args){
String input = "삼십만삼천백십오";
System.out.println(input);
System.out.println(hangulToNum(input));
}
public static long hangulToNum(String input) {
long result = 0;
long tmpResult = 0;
long num = 0;
final String NUMBER = "영일이삼사오육칠팔구";
final String UNIT = "십백천만억조";
final long[] UNIT_NUM = {10, 100, 1000, 10000, (long)1e8 , (long)1e12 };
StringTokenizer st = new StringTokenizer(input, UNIT, true);
while(st.hasMoreTokens()) {
String token = st.nextToken();
int check = NUMBER.indexOf(token); // 숫자인지, 단위(unit)인지 확인한다.
if(check == -1) {
if("만억조".indexOf(token) == -1) {
tmpResult += (num != 0 ? num : 1 ) * UNIT_NUM[UNIT.indexOf(token)];
}else {
tmpResult += num;
result += (tmpResult != 0 ? tmpResult : 1 ) * UNIT_NUM[UNIT.indexOf(token)];
}
num = 0;
}else {
num = check;
}
}
return result + tmpResult + num;
}
}Note) 실행 결과

- 한글로 된 숫자를 아라비아 숫자로 변환하는 예제인다.
- tmpResult는 "만억조"와 같은 큰 단위가 나오기 전까지 "십백천"단위의 값을 저장하기 위한 임시공간
- result는 실제 결과를 저장한다.
- 한글로 된 숫자를 단위(구분자)로 잘라서 토큰이 숫자면 num에 저장하고 단위면 num * 단위 를 tmpResult에 저장.
- 숫자없이 바로 단위로 시작하는 경우에는 num의 값이 0이므로 단위 값을 곱해도 0이되므로 삼항연산자를 이용해서
- num을 1로 바꾼 후, 단위값을 곱하도록 한다.
-> tmpResult += (num != 0 ? num : 1 ) * UNIT_NUM[UNIT.indexOf(token)];
- 만억조 같은 큰단위가 나오면 tmpResult에 저장된 값에 큰 단위 값을 곱해서 result에 저장, tmpResult = 0 초기화
- split()는 데이터를 토큰으로 잘라낸 결과를 배열에 담아서 반환하기 때문에
- 데이터를 토큰으로 잘라낸 결과를 바로바로 잘라서 반환하는 StringTokienizer보다 성능이 떨어질 수 밖에 없다.
2.6 java.math.BigInteger클래스
- long -> 19자리 표현 가능
-> 더 큰 값을 다루려면 BigInteger을 사용한다.
- 생성: 문자열로 숫자를 표현하는 것이 일반적이다.
- BigInteger를 문자열, Byte 배열로 반환하는 메서드
<hide/>
int bigCount() //2진수로 표현했을 때, 1의 개수을 반환
int bitLength() // 2진수로 표현했을 때, 값을 표현하는데 필요한 bit수
boolean testBit(int n) // 우측에서 n+1번째 비트가 1이면true, 0이면 false
BigInteger setBit(int n) // 우측에서 n+1번째 비트를 1로 변경
BigInteger clearBit(int n) // 우측에서 n+1번째 비트를 0으로 변경
BigInteger flipBit(int n) // 우측에서 n+1번째 비트를 전환(1->0, 0->1)Ex)
<hide/>
package javaStudy;
import java.math.*;
public class BigIntegerEx {
public static void main(String[] args) {
for(int i= 0;i < 100; ++i) { //1! ~ 99!까지 출력
System.out.printf("%d! = %s%n", i, calcFactorial(i));
}
}
static String calcFactorial(int n) {
return factorial(BigInteger.valueOf(n)).toString();
}
static BigInteger factorial (BigInteger n) {
if(n.equals(BigInteger.ZERO))
return BigInteger.ONE;
else
return n.multiply(factorial(n.subtract(BigInteger.ONE)));
}
}Note) 실행 결과


- long타입으로는 20!까지 밖에 계산할 수 없지만
- BigInteger로는 99!까지, 그 이상도 가능하다.
- 최댓값: 플마 2의 Integer.MAX_VALUE제곱 , 즉, 10의 6억 제곱
2.7 java.math.BigDecimal 클래스
- double타입으로 표현할 수 있는 값은 범위가 넓지만 정밀도가 최대 13자리 밖에 되지 않고 오차가 생길 수 있다.
- scale: 0 ~ Integer.MAX_VALUE 사이의 값
- BigDecimal도 BigInteger처럼 불변(immutable)이다.
- 반올림 모드 - divide(), setScale()
-> roundingMode: 나눗셈 결과를 어떻게 반올림할 것인지 정한다.
-> scale 몇 번째 자리에서 반올림할 것인가를 정한다.
- roundingMode에 정의된 상수
1) CEILING: 올림
2) FLOOR: 내림
3) UP: 양수일 때는 올림. 음수일 때는 내림
4) DOWN: 양수일 때는 내림, 음수일 때는 올림(UP과 반대)
5) HALF_UP: 반올림(5이상 올림, 5미만 버림) - 일반적으로 알고 있는 반올림
6) HALF_EVEN: 반올림(반올림 자리의 값이 짝수면 HALF_DOWN, 홀수면 HALF_DOWN)
7) HALF_DOWN: 반올림(6이상 올림, 6미만 버림) - 6기준의 반올림
8) UNNECESSARY: 나눗셈 결과가 딱 떨어지는 수가 아니면, ArithmeticException 발생
- java.math.MathContext: 반올림 모드와 정밀도를 하나로 묶어 놓은 것이다.
-> divide()에서는 scale이 소수점 이하의 자리수를 의미하는데
-> MathContext에서는 precision: 정수와 소수점 이하를 모두 포함한 자리수를 의미한다.
- scale의 변경: BigDecimal을 10으록 곱하거나 나누는 대신 scale의 값을 변경하면 같은 결과를 얻을 수 있다.
-> scale을 변경하려면 setScale()을 이용하면 된다.
Ex)
<hide/>
package javaStudy;
import java.math.*;
import static java.math.BigDecimal.*;
import static java.math.RoundingMode.*;
public class BigDecimalEx {
public static void main(String[] args) {
BigDecimal bd1 = new BigDecimal("123.456");
BigDecimal bd2 = new BigDecimal("1.0");
System.out.print("bd1 = " + bd1 );
System.out.print(",\tvalue = " + bd1.unscaledValue());
System.out.print(",\tscale = " + bd1.scale());
System.out.print(",\tprecision = " + bd1.precision());
System.out.println();
System.out.print("bd2 = " + bd2 );
System.out.print(",\tvalue = " + bd2.unscaledValue());
System.out.print(",\tscale = " + bd2.scale());
System.out.print(",\tprecision = " + bd2.precision());
System.out.println();
BigDecimal bd3 = bd1.multiply(bd2);
System.out.print("bd3 = " + bd3 );
System.out.print(",\tvalue = " + bd3.unscaledValue());
System.out.print(",\tscale = " + bd3.scale());
System.out.print(",\tprecision = " + bd3.precision());
System.out.println();
System.out.println(bd1.divide(bd2, 2, HALF_UP));
System.out.println(bd1.setScale( 2, HALF_UP));
System.out.println(bd1.divide(bd2, new MathContext(2, HALF_UP)));
}
}Note) 실행 결과

- BigDecimal을 10으로 곱하거나 나누는 대신 scale의 값을 변경하면 같은 결과를 얻을 수 있다.
- setScale()로 scale을 값을 줄이는 것은 10의 n제곱으로 나누는 것과 같으므로 divide()를 호출할 때처럼 오차가 발생할 수 있고 반올림 모드를 지정해줘야 한다.
'Java > Java의 정석' 카테고리의 다른 글
| Chapter 11 컬렉션 프레임웍(Collection Framework) (0) | 2022.03.02 |
|---|---|
| Chapter 10 날짜와 시간 & 형식화 date, time and formatting (0) | 2022.02.28 |
| Chapter 08 예외처리 Exception Handling (0) | 2022.02.23 |
| Chapter 07 객체지향 프로그래밍 II (0) | 2022.02.22 |
| Chapter 06 객체지향 프로그래밍 I (0) | 2022.02.22 |